
Source: reddit.com
Ever tried finding a meme or photo on Reddit, Twitter, or LinkedIn but couldn't recall the post title? Like many, I often remember the image but not the words, making it nearly impossible to locate. This frustration inspired me to explore a solution: a multimodal search engine that understands both images and text.
Social media platforms host vast amounts of multimedia content, yet their search mechanisms predominantly rely on text. While techniques like keyword and hashtag-based search can be effective, they depend heavily on accurate text metadata (titles, descriptions, and comments).
When this metadata fails to properly describe the media content, users often resort to searching with unrelated terms, or worse, miss relevant content entirely despite it existing on the platform.
To address this, implementing multimodal search capabilities can significantly improve content discovery on platforms like Reddit, particularly for image-heavy communities like r/pics.
For clarity, I'll refer to these text-based approaches as "traditional search" throughout this article.
The Challenge with Traditional Search
Reddit search relies primarily on text matching within titles, self-text, and comments. However, this approach has several limitations:
- Mismatched descriptions: Users often create post titles that don't accurately describe the image content
- Missing context: Important visual elements might not be mentioned in the text
- Cultural references: Memes or references might be difficult to capture in text
- Language barriers: Visual content might be universal, but text descriptions are language-dependent
The Multimodal Solution
CLIP: Bridging Vision and Language
At the heart of this solution lies CLIP (Contrastive Language-Image Pre-training), a neural network that creates embeddings of both images and text in a shared semantic space.
While OpenAI's CLIP model pioneered this approach, this implementation utilizes Jina AI CLIP v1, an optimized variant that extends the original model's capabilities with improved performance on multimodal inputs.
The multimodal embeddings are stored and indexed in Qdrant, a vector database optimized for similarity search operations. When a user submits a search query, it is converted into a text embedding using CLIP, and Qdrant performs a similarity search to find the most similar image or text embeddings.
Results are then ranked using cosine similarity, providing a ranked list of posts that match the user's query.
Technical Implementation
Data Collection and Preprocessing
The data collection process begins by interfacing with Reddit's OAuth API to fetch posts from the r/pics subreddit. For each post, we extract essential metadata including:
- Post title
- Text content
- Permalink
- Direct URL to any attached images
The extracted data forms clean pairs of images and their associated textual metadata, which are then passed to the CLIP embedding process.
Setting up CLIP and Qdrant
The implementation begins with initializing Jina CLIP v1, loaded through the Hugging Face transformers library. This model, configured with a 768-dimensional vector space, serves as our core embedding engine.
Simultaneously, we establish a connection to Qdrant, our vector database, which is configured to store these high-dimensional embeddings using cosine distance metrics for similarity calculations.
from transformers import AutoModel
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams
EMBEDDING_MODEL = "jinaai/jina-clip-v1"
QDRANT_URL = "http://localhost:6333"
COLLECTION_NAME = "reddit_posts"
VECTOR_SIZE = 768
model = AutoModel.from_pretrained(EMBEDDING_MODEL, trust_remote_code=True)
client = QdrantClient(url=QDRANT_URL)
client.create_collection(
collection_name=COLLECTION_NAME,
vectors_config=VectorParams(
size=VECTOR_SIZE,
distance=Distance.COSINE
)
)Embedding Generation and Storage
The system processes Reddit posts through a multi-stage embedding pipeline:
1. Text Embedding
For each post, the title is encoded into a vector representation. If additional text content is present in the post's body, it's processed separately to generate its own embedding.
title_embedding = model.encode_text(post["title"])
selftext_embedding = model.encode_text(post["selftext"])2. Image Embedding
When posts contain images, the system generates visual embeddings using CLIP's image encoder, capturing the visual characteristics in the same semantic space as the text embeddings.
image_embedding = model.encode_image(post["image_url"])3. Vector Storage
Each generated embedding is assigned a unique ID and stored in Qdrant along with its associated post metadata. This storage strategy allows for efficient retrieval of both the semantic vectors and the original content.
import uuid
from qdrant_client.models import PointStruct
embeddings = []
embeddings.append(
PointStruct(id=str(uuid.uuid4()), vector=image_embedding, payload=post)
)
client.upsert(
collection_name=COLLECTION_NAME,
wait=True,
points=embeddings,
)Search Implementation
The search functionality implements a straightforward but effective approach:
- Query Encoding: Convert user queries into CLIP text embeddings
- Vector Search: Perform similarity search in Qdrant
- Result Ranking: Return the top-k most similar results, including both textual and image content
query = "painting of a lady wearing vr glasses"
query_embeds = model.encode_text(query)
limit = 3
# List of similar results to the query
search_results = client.query_points(
collection_name=COLLECTION_NAME,
query=query_embeds,
with_payload=True,
limit=limit,
).pointsResults and Analysis
To demonstrate the capabilities of the multimodal search implementation, we present a series of example queries and their results, alongside corresponding results from Reddit's traditional search.
Note: These searches were performed on Hot posts from r/pics on November 6, 2024. Due to Reddit's dynamic nature, running similar queries at a later date may yield different results.
Evaluation Methodology
For each query, we compare:
- Multimodal Search Results: Our CLIP-powered implementation (white background)
- Traditional Search Results: Reddit's native search functionality (black background)
- Visual Comparison: Side-by-side presentation of images and metadata
The following examples highlight scenarios where multimodal search particularly excels over traditional text-based approaches:
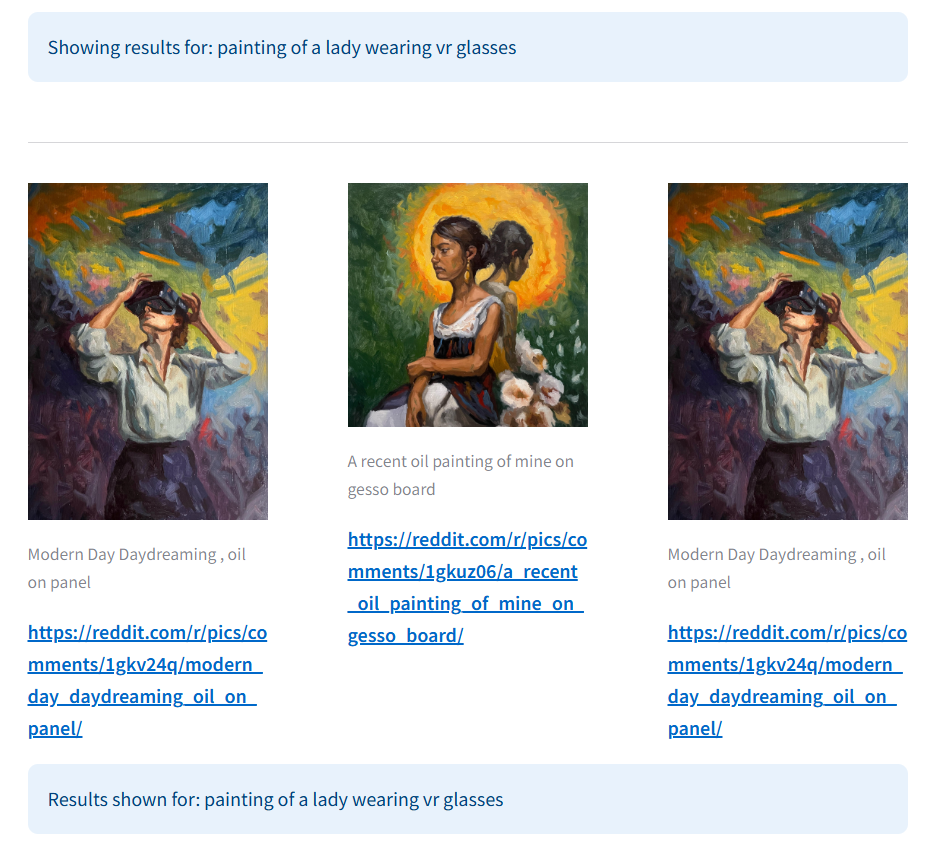
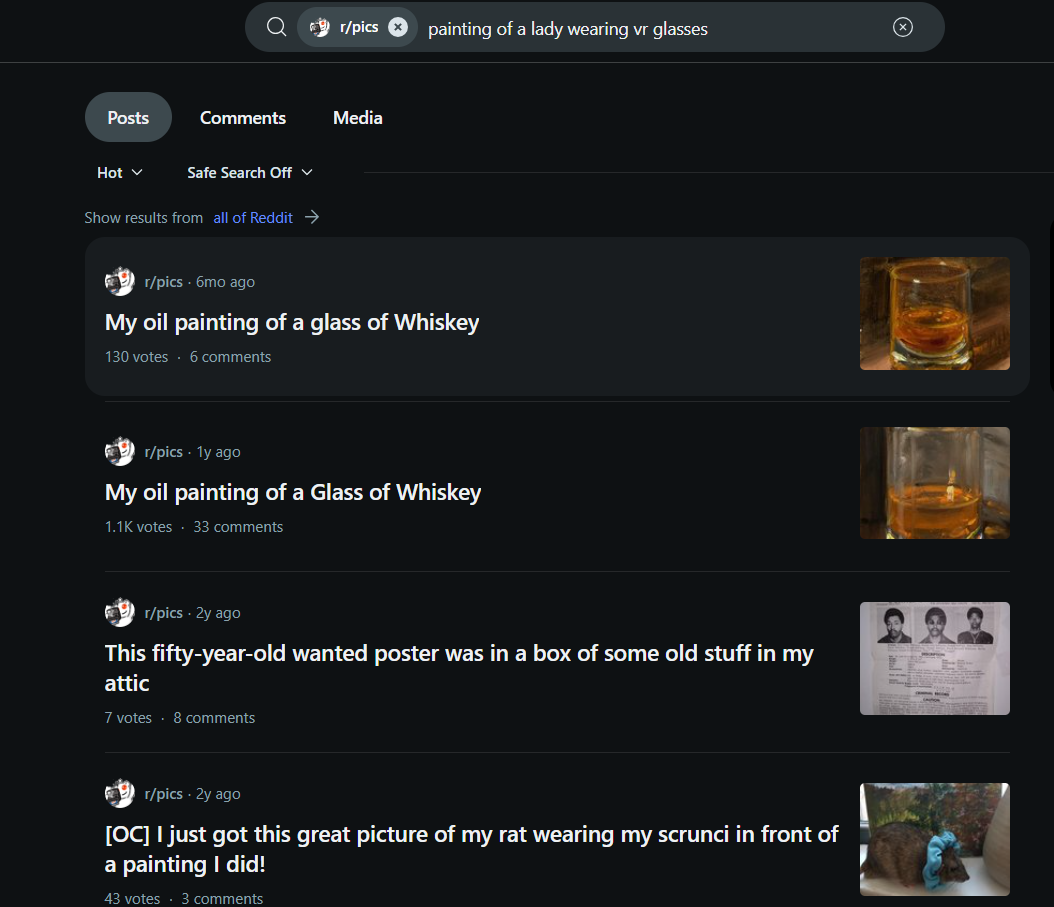
Example 1: Query - "Painting of a lady wearing VR glasses"
The multimodal search results accurately show paintings of a lady wearing VR glasses, aligning with both visual and textual cues. Traditional search, relying on keywords, returns unrelated posts about whiskey glasses, missing the visual context entirely.
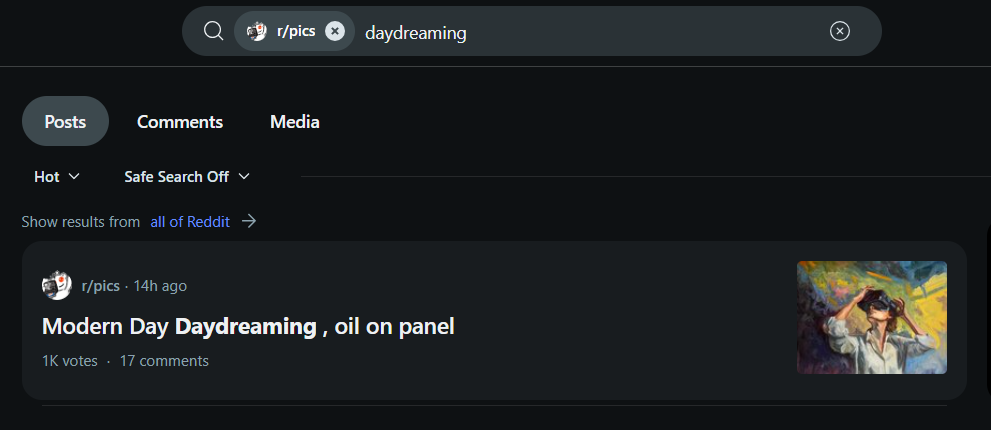
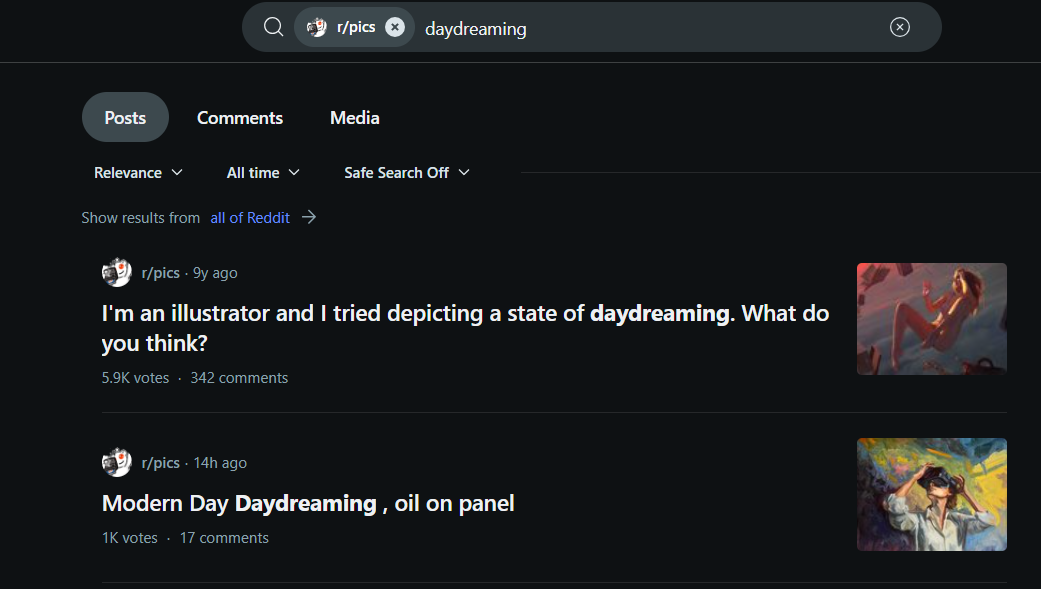
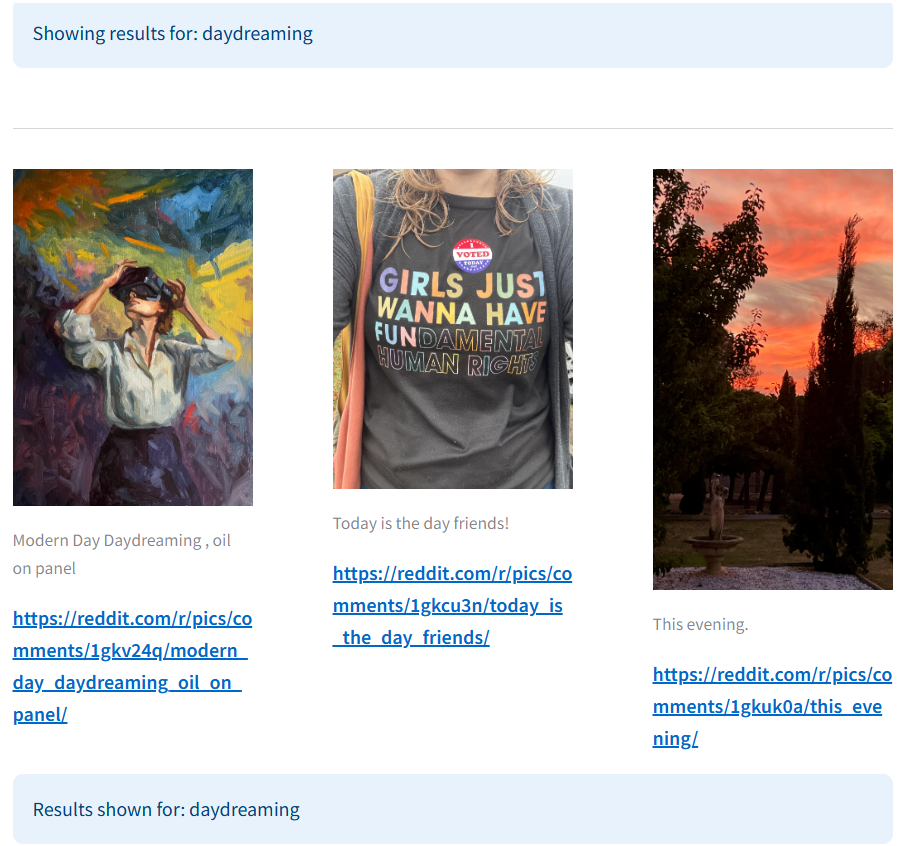
Example 2: Query - "Daydreaming"
Traditional search shows only text-based results, missing the visual essence of "daydreaming." Multimodal search combines text and visuals, presenting relevant images like paintings and landscapes that capture the mood and depth of the concept.
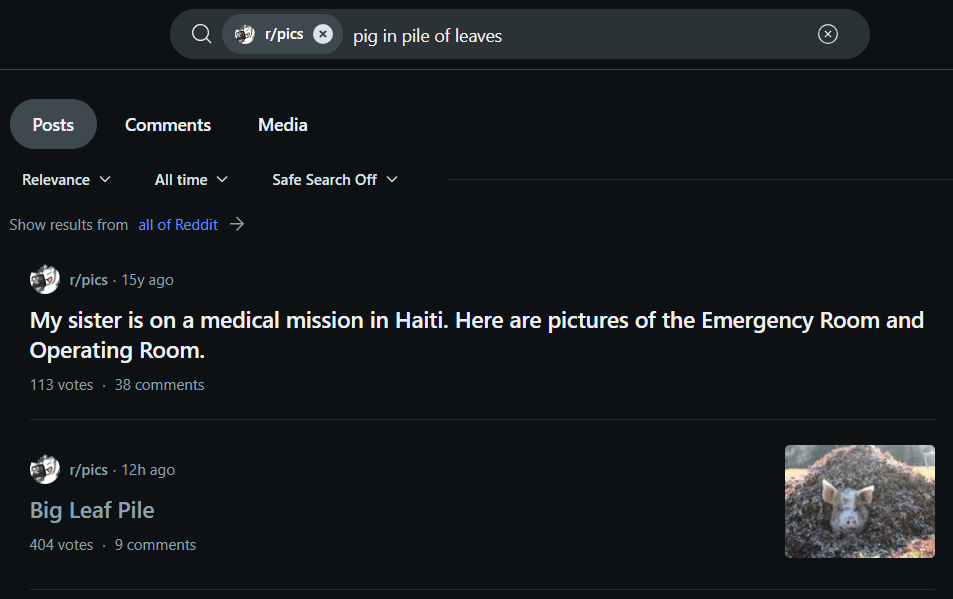
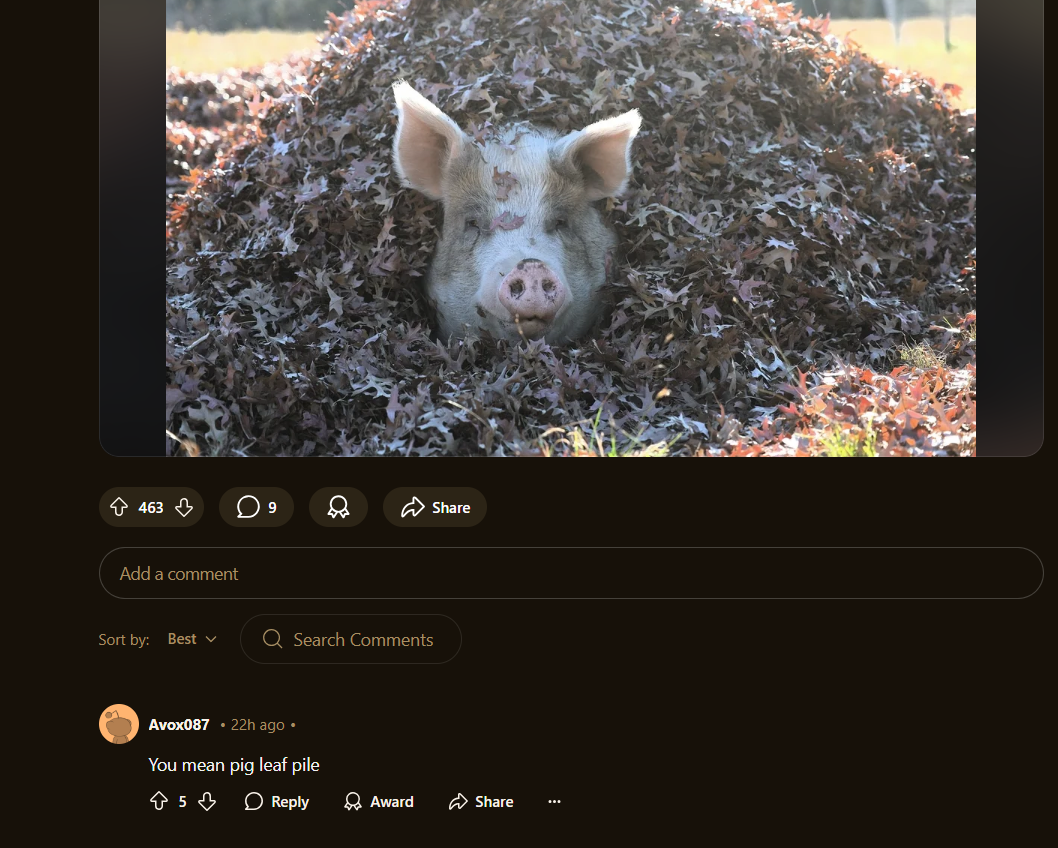
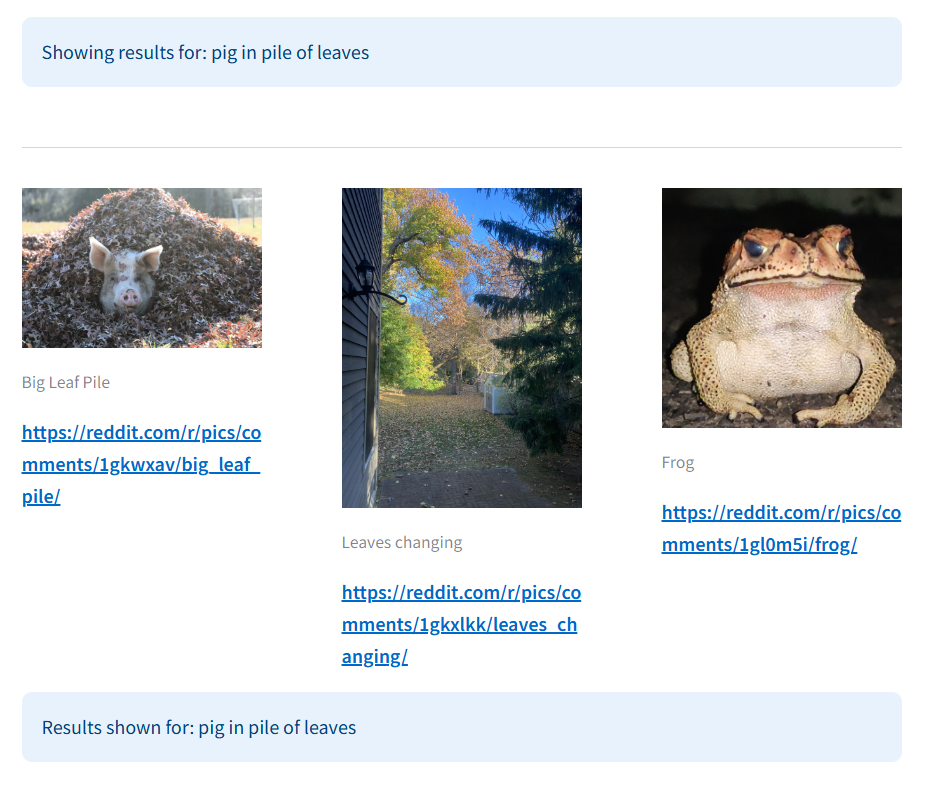
Example 3: Query - "Pig in leaf pile"
In this example, traditional search relied on the title and comments mentioning "pig leaf pile" to return the relevant post, while multimodal search surfaced it independently, without relying on comment context.
Key Insights
While this exploration is qualitative in nature, it provides valuable insights into how multimodal search can complement traditional text-based approaches. The examples demonstrate clear advantages in scenarios where:
- Visual content doesn't match textual descriptions
- Cultural or contextual references are primarily visual
- Users search with descriptive rather than exact terminology
A comprehensive comparative analysis using LLM-based evaluation metrics is planned for future work.
Conclusion
Multimodal search offers a transformative dimension in content discovery, especially on media-rich platforms like Reddit. By leveraging both text and image data, it bridges the gap left by traditional search methods, enhancing users' ability to find posts that resonate visually and contextually.
Key Takeaways
- Visual Understanding: CLIP enables search engines to understand images beyond their textual descriptions
- Improved Discovery: Users can find content using natural, descriptive language rather than exact keywords
- Platform Agnostic: The approach can be adapted to any platform with multimedia content
- Complementary Technology: Works best when combined with traditional search methods
As social media grows in complexity and visual content dominates our digital interactions, this approach could redefine how we explore, recall, and interact with content online.
Next Steps & Future Work
- Implement quantitative evaluation metrics using LLM-based assessment
- Explore real-time indexing capabilities for dynamic content
- Investigate cross-platform multimodal search applications
- Develop user interface improvements for search result presentation
Ready to explore multimodal search yourself? Find the complete source code and implementation details on GitHub:
Repository: multimodal-search
License: MIT